


Mixing Topic Models and Citations
A better way to find high-level topics

One of the weaknesses of my earlier work using topic models, my History of Journals book, was that it required a two step approach.
I used topic modeling to assign the articles to one of 90 topics. But 90 is too many for all but the most obsessive readers to follow, and the 90 didn’t quite match our intuitive categories of philosophy papers. So I more-or-less manually assigned each of those 90 topics to one of twelve categories, and those categories did a lot of the organisational work in the book.
In this respect I was (I think) following best practice in the field. It’s standard to build fine-grained models, then have at least some of the reporting involve clusters, or some other grouping of the topics.
There is a real upside to doing things this way. Sometimes we want to explore the data in both a fine-grained and coarse-grained way, and having topics plus clusters of topics lets us do both.
But there is also a big downside. The clustering is usually done by hand, which is not only work, it means that the researcher biases get introduced. The nice feature of topic models that they are willing to say they are unsure, and assign entries partially to one topic and partially to another, typically gets lost in the clustering. It would be good to have topic models where the topics corresponded to the familiar categories of philosophical discourse.
The problem, or at least my problem when I tried to do this, is that it doesn’t work. I couldn’t get small n topic models to correspond to familiar philosophical kinds. The only way I could figure out how to make topic models tell us anything about familiar categories like Epistemology or Metaphysics was to use large numbers of topics, and then cluster.
I may have now figured out a way around this.
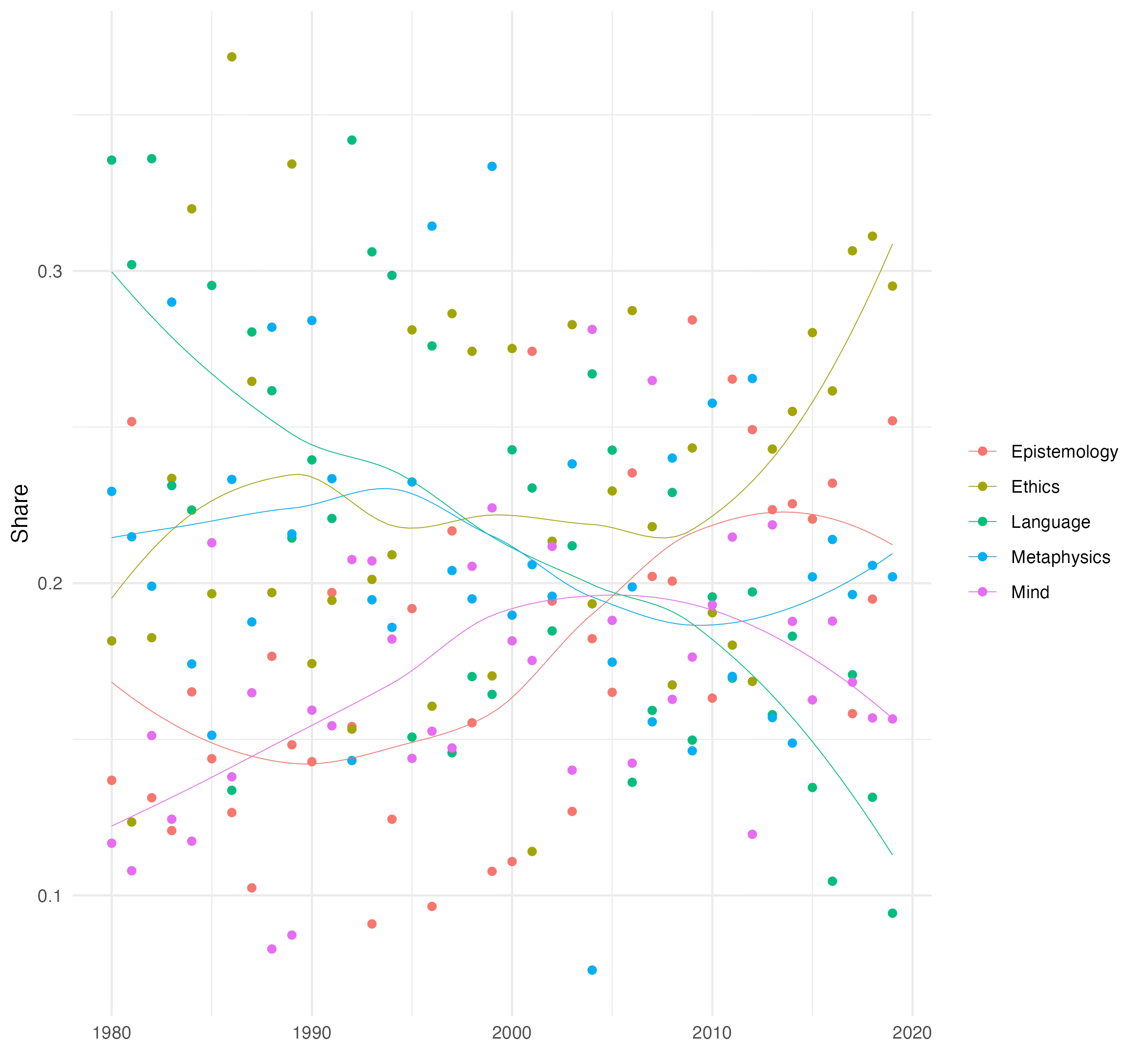
I’ve been building some models of articles published in Philosophical Studies from 1980 to 2019. As well as the text of these articles, I also have a record of which of them cite each other. So here’s what I did.
I built a lot of 5-topic models of the Philosophical Studies articles. I settled on 5 because given what Philosophical Studies publishes, most articles fit into one of these five groupings:
Ethics (including meta-ethics and a little political philosophy)
Language (including a small amount of logic)
Epistemology (including formal epistemology)
Mind (especially perception)
Metaphysics (including some metaphysics of science)
Could a five topic model find these five topics? Not always. But it could sometimes.
So what I did was look for models where articles tended to get classified in the same topic as the articles that they cited. More precisely, I looked for models where the average classification of articles in a topic was as similar as possible for the average classification of articles cited by articles in a topic.
I did this in stages.
First I randomly came up with 1000 possible starting points for models; these models usually start with a random distribution. I kept the 100 that had the highest percentage of citations being within a category.1
Second, I did five ‘iterations’ on each of those 100 models. Usually the way a model is built is that it starts with a random distribution, then engages in an iterated search for the nearest equilibrium-like point.2 Normally it takes 20-30 iterations to find a point the model is stopping at. I told it to stop after 5, and see how well each of these 100 models was doing at classifying articles the same way it classifies the pieces that article cites.
Third, I found the ten best articles after these five iterations.3 I did 95 more iterations on each of these. That’s already much more than LDA models usually require, but it seemed to create better and better models. At least, it created models where the classification of articles better and better resembled the classification of the articles they cite.
Fourth, I found the best of those after 100 iterations (5 at the second stage, plus 95 at the third stage), and did 900 more iterations. This was absurd overkill, and I’ll do many fewer if I apply this technique to larger data sets. But it only took 90 minutes or so, so it wasn’t too bad.
The result is the LDA I’ve described at this link. I can’t figure out how to get all the tables, citations, and graphs into Substack, so I’m just going to link it here.
I think it’s a fairly good model actually.
At that link I’ve highlighted papers where the model isn’t sure how to classify them. And in most cases, I think the model gets things right, even when it is unsure. You should classify papers on epistemic norms as being somewhat in Epistemology, and somewhat in Ethics. You should classify papers on physicalism as being somewhat in Mind and somewhat in Metaphysics. I’m obviously biased, but I think it does a pretty good job at getting the clear cases right, and being unsure about the cases where a particular classification would be arbitrary.
So this might be a useful technique. Building a bunch of noisy models, checking how well they match up with citation data, and then putting the computer to work refining the ones that do well by that standard, seems to build a sensible small n model.
One last note.
Deep down, I’m not sure how much future there is in bag-of-words techniques like topic modeling. I think using citation data produces a better topic model than I’d been able to come up with previously. But maybe the whole technique will be superseded by modern classifiers. Even so, I suspect there is some potential for using citation data as a way of steering/training the modern classifiers that will/may supersede approached like topic modeling.
This is rough; I can go over more of precisely how I selected the models to keep if anyone is interested.
There aren’t actually any equilibria in the relevant sense; but some points are sufficiently like an equilibrium to be a reasonable stopping point.
At this point I started judging how well a model was doing the following way. Remember that an LDA gives a probability to each article being in each of the 5 topics. For a particular topic, say Mind, I selected the articles in that topic; i.e., more likely to be Mind articles than anything else. Across those articles, I calculated the average probability (according to the model) of an article being in each topic. I also calculated, across the articles those articles cited, the average probability of the cited article being in each topic. That gave us two five-valued vectors, which we can easily interpret as literal vectors in a five-dimensional space. The cosine of the angle between these two vectors is a decent measure of how similar they are. And that’s what I’m using.